
서론
N+1 문제란
Spring Data JPA를 사용하다보면 N+1 문제에 대해서 많이들 겪곤 한다.
N+1 문제란 관계형 데이터베이스에서 일반적으로 발생하는 성능 이슈다. 예를 들어, 게시물(Post)과 사용자(User) 그리고 댓글(Comment)이라는 엔티티가 있다고 가정해 보자. 게시물 목록을 가져올 때, 각 게시물에 대한 사용자 정보와 댓글 정보를 함께 가져와야 하는 경우 N+1 문제가 발생할 수 있다 .
Fetch Join
이러한 문제를 해결하기 위해 Fetch Join을 사용하여 연관된 엔티티를 한 번의 쿼리로 함께 로드할 수 있다.
즉 Fetch Join은 관계형 데이터베이스에서 조인을 통해 필요한 데이터를 한 번에 가져오는 방식이다.
Fetch Join 사용 X - 연관된 테이블에 등록된 N개의 정보를 N개만큼 추가적으로 쿼리가 나간다.


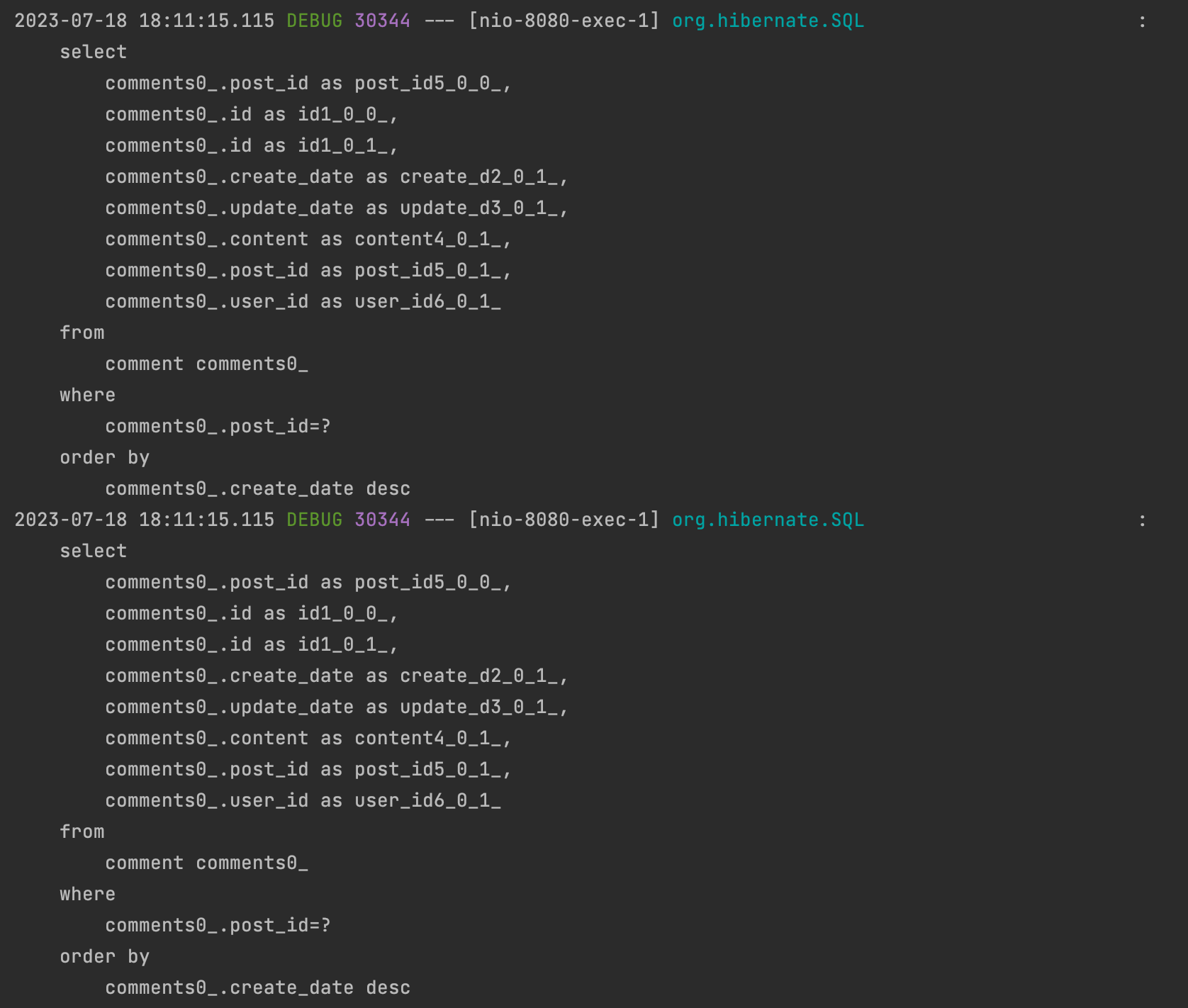
Fetch Join 사용 O - 단 한 번의 쿼리로 필요한 데이터를 모두 가져온다.
but! 오늘 알아 볼 문제는 N+1과 Fetch Join의 사용법은 아니다.
제목에서 봤듯이, Fetch Join과 CountQuery를 사용한 페이징 최적화가 다룰 주제이다.
(서론이지만 뭔가 내용이 많다는 건 그만큼 중요한 내용이겠지? 라고 생각한다.)
페이징
JPA를 사용하다가 컬렉션을 조회해야 하는 경우가 종종있다.
컬렉션을 조회 할때, 기준 엔티티와 대상 엔티티가 1:N인 경우, 조인될 때 대상 엔티티의 갯수만큼 N개의 쿼리가 추가되는 문제가 발생한다. 이때 쿼리문에 DISTINCT 키워드를 사용해주면 문제가 쉽게 해결된다.
하지만 컬렉션 조회를 하는 경우 페이징이 불가한다는 치명적인 문제가 있다. (자세한 내용은 영한님 강의 - 자바 ORM 표준 JPA 프로그래밍 참조!)
- 컬렉션을 페치 조인하면 일대다 조인이 발생하므로 데이터가 예측할 수 없이 증가한다.
- 일다대에서 일(1)을 기준으로 페이징을 하는 것이 목적이다. 그런데 데이터는 다(N)를 기준으로 row 가 생성된다.
- Post를 기준으로 페이징 하고 싶은데, 다(N)인 Comment를 조인하면 Comment가 기준이 되어버린다.
해결책 - BatchSize
일대다 관계에서 컬렉션 조회시 지연 로딩의 성능 최적화를 위해서 BatchSize라는 것을 적용시킬 수 있다. 물론 페이징까지 가능한 방법이다.
- apllication.yml에 hibernate.default_batch_fetch_size를 적용한다.
- 필드별 개별 최적화를 하기 위해서는 @BatchSize 어노테이션을 추가한다.


이 두 방법중 하나를 선택해서 쿼리 호출 수를 1+N -> 1 +1 (조인하는 테이블 수 만큼) 로 줄일 수 있다.
따라서 컬렉션을 최적화 하기 위해서는 두 가지 방법이 존재하는데,
1. 페이징 필요 => hibernate.default_batch_fetch_size , @BatchSize 로 최적화
2. 페이징 필요X => 페치 조인 사용
중에 선택하면 될 것 같다!
적용 사례
나의 전반적인 흐름을 알려주자면
- 단순 List로 Post의 전체를 조회하고 있는 상황이었다. (Fetch Join 적용)
- 하지만 프론트단도 구현하다 보니, 전체 게시물이 많아졌을 때, 아래로 끝 없이 내려가는 것이 불편하다고 느꼈다.
- 페이징을 마음 먹었다.
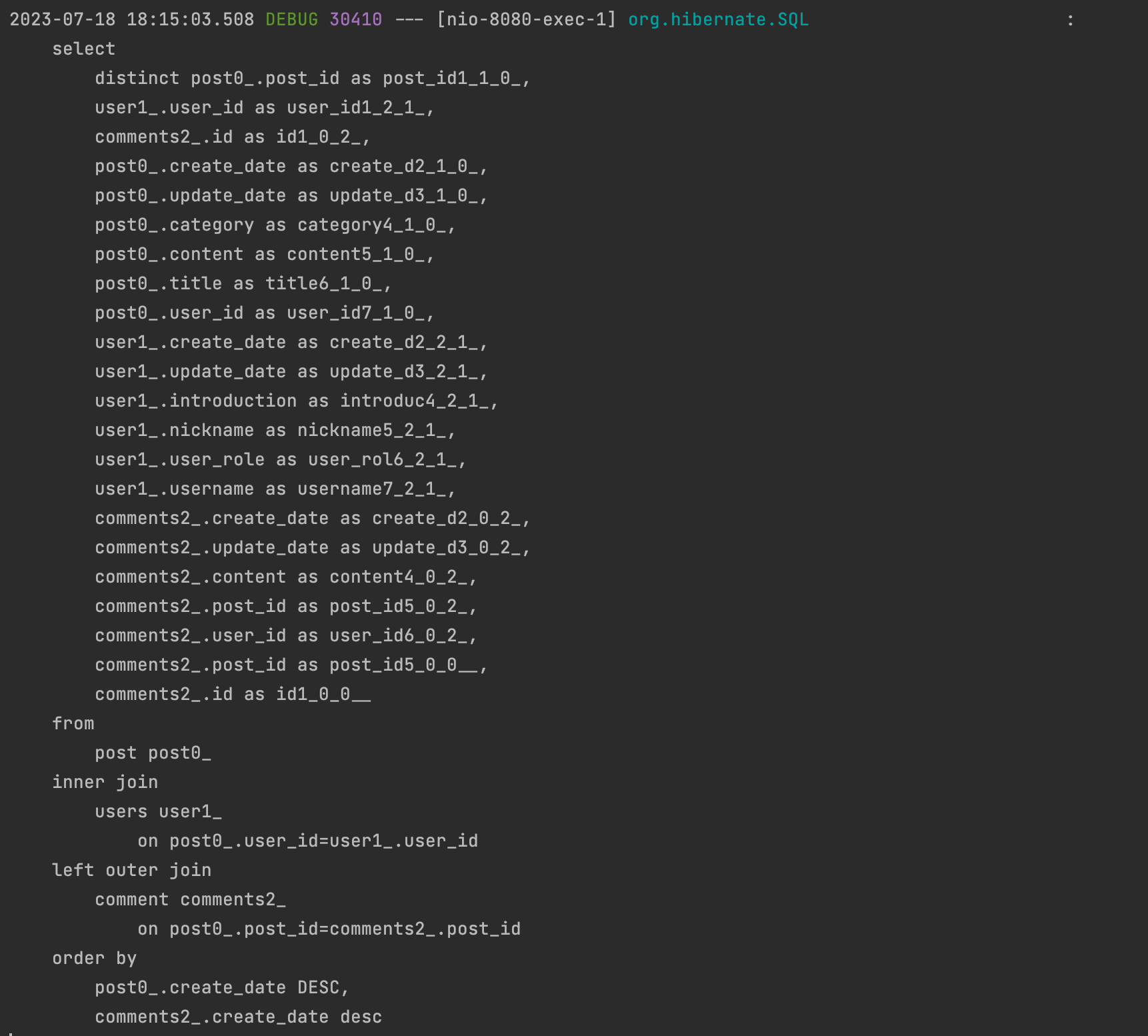
아래는 3번(페이징)을 적용시킨 후 였다.



이 게시물 가장 위의 Fetch Join을 적용 시키지 않았을 때에 비하면 쿼리수가 현저히 줄어든 것을 볼 수 있다.
따라서
페이징 사용 X + Fetch Join 적용 X : 어마어마한 N+1 문제로 쿼리 대량 발생
페이징 사용 X + Fetch Join 적용 O : 단 한번의 쿼리로 조회 가능
페이징 사용 O + Fetch Join 적용 X (불가) + BatchSize 적용 : N+1의 문제는 현저히 줄어듬. 하지만 단 한 번의 쿼리는 아니다.
의문, 그리고 실패
여기서 나는 일대다 컬렉션 최적화 및 페이징 사용시 단 한 번의 쿼리만 나가게 할 수 없을까? 라는 의문을 가지게 되었다.
그래서 BatchSize를 적용시키고, 페이징을 사용하는 Repository 메서드 쿼리에 당당히 fetch 키워드를 넣게 되었다.

결과는

Caused by: org.hibernate.QueryException: query specified join fetching,
but the owner of the fetched association was not present in the select list위와 같은 에러가 떴다.

원인 및 해결 방안
하이버네이트에서 fetch join 사용 시에, 페이징에 필요한 Count 쿼리를 자동으로 만들어주지 못한다고 한다.
그래서 아래와 같이 Count Query를 명시해주어야 한다. (Spring Data JPA에서는 @Query 어노테이션에서 편하게 작성이 가능하다.)

결과

단 한 번의 쿼리로 관련된 데이터를 모두 가져온다!!!

RestController에서 지정해준대로 잘 페이징이 되었다.
또한 ViewController의 화면단에서도 요청한 대로 5개씩 역순으로 잘 노출이 되었다!


하지만, countQuery를 많이 사용하면 당연히 DB에 많은 부하를 줄것이다. 특히 데이터가 많거나 복잡한 쿼리일 경우에는 오히려 성능 저하의 원인이 될 수도 있을 것이다.
영한님께서도 카운트 쿼리 분리는 실무에서 매우 중요하다고 말씀해 주셨고, 또한 전체 카운트 쿼리는 매우 무겁다. 라고도 말씀하셨다!!
느낀점
N+1, BatchSize, 페이징등 이론적으로만 알고있는 문제를 직접 프로젝트를 해보고 겪어보니 어떻게 좋지 않고, 위험한지 알게 되었다.
또 각 문제들을 어떻게 처리할 수 있는지를 실제로 접목 시켜보니, 역시 머리로 이해하고 넘어가는 것이 아니라 실제 프로젝트에 적용시켜봐야 내것이 된다라는 것을 더욱 깨달았다.
또한 직접적인 문제는 해결했으니, countQuery가 어떠한 이유 때문에 이러한 것을 가능하게 해주는지도 추가적인 공부도 필요하다.
참고 사이트
https://stackoverflow.com/questions/21549480/spring-data-fetch-join-with-paging-is-not-working
Spring-Data FETCH JOIN with Paging is not working
I am trying to use HQL fetching my entity along with sub-entities using JOIN FETCH, this is working fine if I want all the results but it is not the case if I want a Page My entity is @Entity @D...
stackoverflow.com
실전! 스프링 데이터 JPA - 인프런 | 강의
스프링 데이터 JPA는 기존의 한계를 넘어 마치 마법처럼 리포지토리에 구현 클래스 없이 인터페이스만으로 개발을 완료할 수 있습니다. 그리고 반복 개발해온 기본 CRUD 기능도 모두 제공합니다.
www.inflearn.com
'JPA' 카테고리의 다른 글
| JPA/DDD 관점에서의 직접 참조/간접 참조 (1) | 2024.10.11 |
|---|---|
| 연관 관계가 Lazy Loading일 때, 해당 엔티티를 사용하는 메서드에 @Transactional이 없다면? (0) | 2024.08.22 |
| 영속성 컨텍스트란? (0) | 2023.02.03 |